前言
Logstash 是 Elastic Stack 的中央数据流引擎,用于收集、丰富和统一所有数据,而不管格式或模式。当与Elasticsearch,Kibana,及 Beats 共同使用的时候便会拥有特别强大的实时处理能力。
本章中核心重点包括:
- Logstash 概念与术语
- 内部架构和重要设置
1. Logstash的工作原理
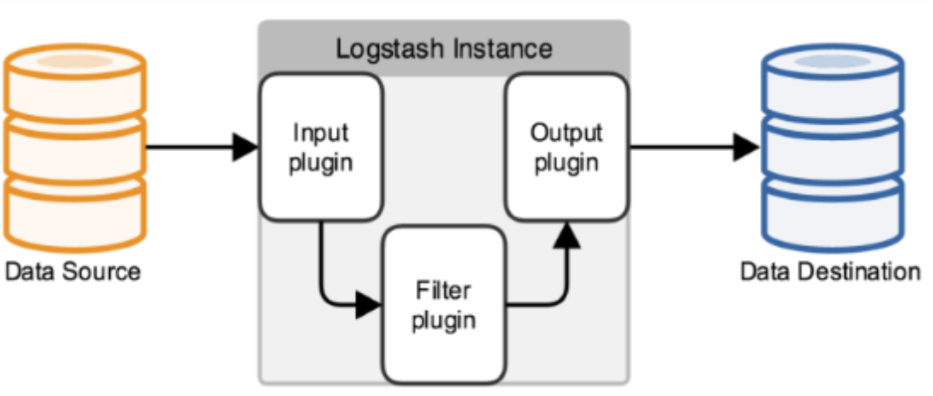
logstash的事件处理流程分为三个阶段:inputs - - - > filers - - - > outputs,即 接受输入的日志 —> 按过滤条件进行处理日志 —> 输出过滤后的日志。其支持所有抛出的日志类型数据。
简单的结构图:
1.1 inputs 输入
常见的输入有以下几点:
1)syslog:监听514端口上的系统日志信息
2)udp:监听指定的udp端口
3)file: 从文件系统的文件中读取日志信息,类似tail -f命令
4)redis:从redis service中读取
5)beats:从filebeat中读取
1.2 filters 日志过滤
常用的过滤器有以下几个:
1)grok:logstash中最重要的插件,其能解析任意的文本数据,并转化为具有格式化的数据。可以配合正则表达式使用
2)mutate:对字段进行处理。如对字段进行删除、修改、重命名、替换等操作
3)geoip:添加地理位置信息,用户kibana图形化显示使用
4)drop:丢弃部分数据
5)clone:拷贝数据,这个过程可以添加或删除字段
1.3 outputs 输出
常用的输出 有以下几个:
1)elasticsearch:用es服务进行数据的存储
2)file:将输出数据保存到文本中
3)graphite:将数据发送到图形化组件中
4)json:使用json格式数据进行编码 / 解码
5)multiline:将多个事件的数据汇总为一个单行数据
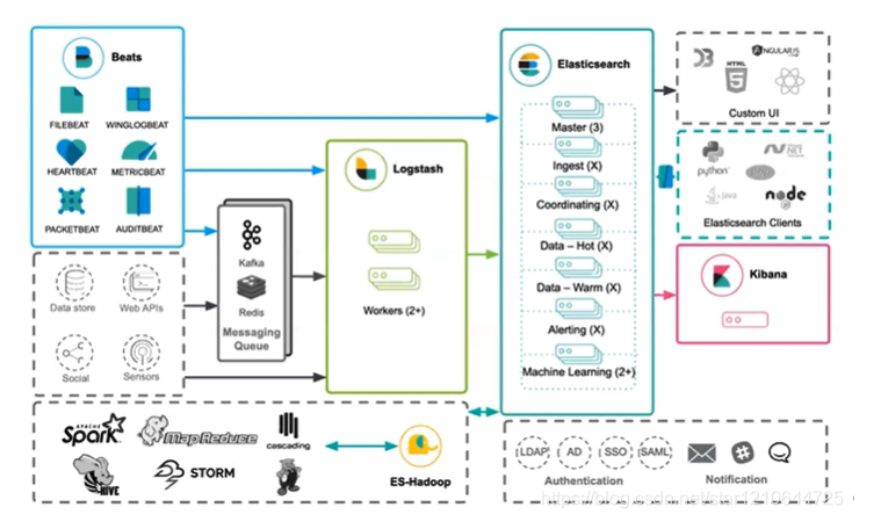
2. logstash在数据分析中的位置
logstash在整个结构中起到数据采集,格式化,数据过滤等处理,最终数据推到ES做存储。其logstash在整个架构中的图解如下: